
13 juillet 2026
Écrire une user story efficace : le guide complet
Une user story décrit un besoin logiciel du point de vue de l'utilisateur. Définition, utilité et méthode pour en rédiger d'efficaces, exemples à l'appui.
Lire l'article →
Blog
Nos retours d'expérience, notre veille et nos analyses sans filtre sur l'automatisation, l'intelligence artificielle,la QVCT et la performance.
De la machine de Turing aux premiers réseaux de neurones : plongez dans la grande histoire de l'intelligence artificielle. Une série d'articles pour comprendre les origines, les mythes et les évolutions de l'IA.
Voir la série →
Comment l'IA transforme-t-elle réellement nos métiers ? Découvrez nos entretiens authentiques et nuancés avec des professionnels qui intègrent (ou questionnent) l'intelligence artificielle dans leur quotidien.
Voir la série →

28 mai 2026
LVLUP est désormais référencé comme Activateur France Num par la Direction générale des entreprises. Voici ce que ce label couvre concrètement, et pourquoi ça devrait changer la façon dont vous choisissez votre prestataire numérique.
Lire la suite →

19 mai 2026
23 minutes pour retrouver sa concentration après une interruption. Le Deep Work en entreprise se joue au niveau de l'organisation. Retour d'expérience et démonstration chiffrée.
Lire la suite →
28 avril 2026
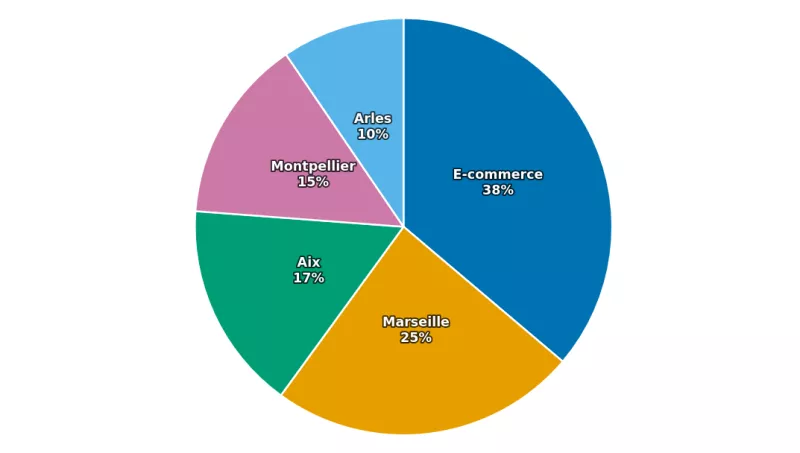
Entre 20 et 30 % du temps de travail est consacré à chercher des informations. On décortique ce coût caché et les leviers concrets pour le réduire.
Lire la suite →

6 avril 2026
Une étude INSEAD sur 515 startups montre que le vrai frein au ROI de l'IA n'est pas l'outil, mais la capacité à identifier où il crée de la valeur. Décryptage du 'mapping problem'.
Lire la suite →

1 avril 2026
OpenAI ferme Sora, son générateur vidéo IA à 1 million $/jour. Derrière l'échec apparent, un pivot stratégique vers les agents IA et la robotique. Décryptage.
Lire la suite →
30 mars 2026
Mistral AI emprunte 830 millions de dollars pour un data center de 13 800 GPU en France. Analyse du pari financier, de l'écart avec les géants américains, et de la stratégie de souveraineté IA européenne.
Lire la suite →

30 mars 2026
Fruit Love Island, une télé-réalité 100% générée par IA, a explosé sur TikTok avant d'être supprimée. Retour sur un phénomène qui révèle où l'IA frappe vraiment dans l'audiovisuel.
Lire la suite →

29 mars 2026
Découvrez pourquoi LVLUP a lancé le package laravel-user-is-admin. Une alternative simple et pragmatique pour gérer les accès de vos MVP Laravel sans over-engineering.
Lire la suite →

29 mars 2026
Suivez l'activité de vos utilisateurs Laravel sans surcharger votre base de données avec laravel-user-last-seen-at. Une solution pragmatique signée LVLUP pour vos campagnes CRM.
Lire la suite →

26 mars 2026
LVLUP s'associe à Syazen pour l'hébergement et l'infogérance de vos logiciels. Code sur-mesure, serveurs haute fiabilité et sécurité pour vos projets.
Lire la suite →

16 mars 2026
Lior Chamla, développeur et formateur, livre son regard sans filtre sur l'IA : entre gains de productivité spectaculaires et inquiétudes sur l'apprentissage des juniors.
Lire la suite →
9 mars 2026
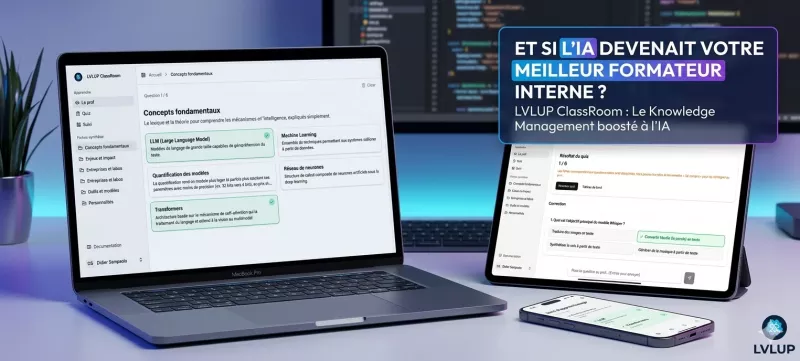
Découvrez LVLUP ClassRoom, notre IA dédiée au Knowledge Management. Transformez votre documentation interne en un parcours d'apprentissage interactif et sur-mesure.
Lire la suite →

15 février 2026
LVLUP fête ses 8 ans. Récit d'un pivot stratégique : passer du "side project" technique à l'agence d'efficacité opérationnelle qui concilie ROI et QVCT.
Lire la suite →

13 février 2026
Comment automatiser un process critique sans créer d'usine à gaz ? Découvrez notre méthodologie appliquée à la gestion de paie, entre Lean et rigueur technique.
Lire la suite →

14 janvier 2026
LVLUP ajoute une nouvelle brique à son site : un Laboratoire unifié avec des micro-outils issus de notre R&D interne, accessibles à l'usage. Notre offre de consulting, développement et formations reste inchangée.
Lire la suite →

6 janvier 2026
Runway, Sora, Kling, HeyGen, Wan… Quel générateur vidéo IA choisir en 2026 ? Comparatif complet par usage, prix et qualité pour PME, agences, créateurs et artistes.
Lire la suite →

18 décembre 2025
Mathieu Flaig dirige le conseil RH et la transformation digitale chez SQORUS. Sa vision de l'IA : une obligation de réinvention pour les entreprises, où l'exigence et la curiosité font la différence.
Lire la suite →

16 décembre 2025
Directeur général de Silver Valley, Romain Ganneau partage sa vision pragmatique de l'IA : entre usages transformateurs dans la santé, limites économiques et dérives inquiétantes.
Lire la suite →

3 décembre 2025
Le code de ChatGPT révèle des préparatifs publicitaires. Analyse des indices, de la pression économique sur OpenAI et des risques pour les utilisateurs.
Lire la suite →

29 novembre 2025
Valoriser les heures supplémentaires détruit votre productivité et chasse vos talents. Découvrez pourquoi les dirigeants qui récompensent le présentéisme sabotent leur propre entreprise.
Lire la suite →

26 novembre 2025
Le management traditionnel basé sur le contrôle est mort. Apprenez comment la Théorie de l'Autodétermination et l'exemple de Netflix redéfinissent le leadership moderne pour booster motivation et performance.
Lire la suite →

25 novembre 2025
Anthropic lance Claude Opus 4.5 avec un score de 80,9% sur SWE-bench. Analyse de ce modèle IA qui mise sur la fiabilité plutôt que sur les performances brutes.
Lire la suite →

24 novembre 2025
ChatGPT échoue à 92% sur la génération de planning hospitalier. On vous montre pourquoi une méthode des années 60 est 100% fiable en < 1 seconde.
Lire la suite →

17 novembre 2025
TOON va-t-il remplacer le JSON pour les LLM ? Explorez ce nouveau format qui réduit les tokens, ses bénéfices réels et pourquoi il ne révolutionne pas tout.
Lire la suite →

17 novembre 2025
Découvrez comment la théorie d'Herzberg sur Adam et Abraham révèle les vrais leviers de motivation de vos équipes. Au-delà du salaire, agissez sur l'engagement durable.
Lire la suite →
![[Étude] Presse française versus IA : qui bloque quel bot ?](https://www.lvlup.fr/storage/img/blog/medium/paperboy-ia-etude.webp)
2 novembre 2025
Étude exclusive sur 1132 sites de presse français : 23% bloquent les robots d'IA. CCBot en tête, suivi de GPTBot. Découvrez les stratégies de blocage des éditeurs.
Lire la suite →

31 octobre 2025
Votre projet digital est devenu trop complexe et n'avance plus ? Découvrez pourquoi 'faire simple' (YAGNI) est la clé pour sauver votre budget et vos délais.
Lire la suite →

27 octobre 2025
Retour d'expérience sur Laravel Boost, le package officiel de Laravel pour améliorer la génération de code, embarqué directement dans votre IDE.
Lire la suite →

20 octobre 2025
Je vois régulièrement passer des posts sur Linkedin, de gens qui se vantent d'avoir automatisé leur process de recrutement grâce à un script N8N. La promesse est sympa, mais que dit la loi française à ce sujet ?
Lire la suite →

20 octobre 2025
Les années 80 voient l’essor des systèmes experts, avant une nouvelle désillusion qui mène au deuxième hiver de l’IA.
Lire la suite →

18 octobre 2025
Le 16 octobre 2025, Anthropic a lancé les Claude Skills. Cette fonctionnalité permet d'expliquer au LLM comment réaliser des tâches complexes, via des fichiers Markdown et scripts.
Lire la suite →

16 octobre 2025
Pendant que l'Europe se concentre sur la régulation de l'IA avec l'AI Act, la Chine l'enseigne massivement dès l'école primaire. Analyse d'un enjeu de souveraineté qui se joue maintenant.
Lire la suite →

14 octobre 2025
La Californie impose des garde-fous aux chatbots IA avec la loi SB 243. Décryptage des obligations de transparence et de sécurité pour protéger les mineurs.
Lire la suite →
14 octobre 2025
Les années 70 sont souvent vues comme une période creuse pour l’IA. En réalité, c’est une décennie paradoxale : un hiver pour les financements, mais aussi le terreau des grandes avancées de la décennie suivante.
Lire la suite →

13 octobre 2025
Découvrez pourquoi l'IA Overviews de Google n'est pas déployée en France. Une analyse des blocages réglementaires (droits voisins) et de l'impact sur notre compétitivité.
Lire la suite →

9 octobre 2025
Tesla Optimus fait du kung-fu à Hollywood, mais la vraie révolution robotique se joue ailleurs : dans votre panier à linge. Comparatif 2025 des robots humanoïdes.
Lire la suite →
9 octobre 2025
Dans les années 60, ELIZA bluffe par ses conversations, Shakey apprend à agir. Deux jalons fondateurs de l’intelligence artificielle.
Lire la suite →

7 octobre 2025
Analyse stratégique de l'affrontement entre les modèles éditoriaux de Wikipédia et de Grokipedia, et les risques de perte de souveraineté sur l'information à l'ère de l'IA.
Lire la suite →

6 octobre 2025
Avant ELIZA et Shakey, un chercheur imaginait déjà une machine capable d’apprendre comme un cerveau. Le perceptron de Rosenblatt inaugure la grande aventure des réseaux de neurones artificiels.
Lire la suite →
4 octobre 2025
OpenAI lance l'achat direct dans ChatGPT, déclenchant une guerre des standards avec Google. Analyse d'une révolution pour l'e-commerce et le futur du GEO.
Lire la suite →

4 octobre 2025
L'école Alpha remplace les profs par une IA pour le savoir académique. Est-ce une innovation radicale ou un gadget pour riches ? Analyse d'un modèle qui redéfinit la valeur de l'humain.
Lire la suite →
4 octobre 2025
Claude 4.5 détecte les tests et adapte son comportement. Cette capacité révèle un problème majeur : l'écart croissant entre la puissance de nos IA et notre capacité à les auditer et contrôler.
Lire la suite →

3 octobre 2025
Sora 2 industrialise le 'brain rot', mot de l'année 2024. Face à ce déluge de contenu IA, l'authenticité devient le seul atout stratégique pour les entreprises.
Lire la suite →

2 octobre 2025
Et si "perdre du temps" était en réalité la seule façon de rester compétitif sur le long terme ?
Lire la suite →

30 septembre 2025
En 1956, la conférence de Dartmouth marque la naissance officielle de l’intelligence artificielle comme discipline scientifique.
Lire la suite →

23 septembre 2025
Alan Turing déplace le débat : inutile de définir la pensée, demandons si une machine peut nous en donner l’illusion. Une idée qui est au cœur de l’intelligence artificielle.
Lire la suite →

22 septembre 2025
Vos prompts d'IA sont moins efficaces sur les nouveaux modèles ? Découvrez pourquoi il faut les réécrire en fonction des biais de format, de position et de personnalité de chaque IA pour améliorer vos résultats.
Lire la suite →

22 septembre 2025
Le Turc mécanique (1770), automate joueur d’échecs truqué, a marqué l’imaginaire européen comme la première illusion d’intelligence artificielle.
Lire la suite →
20 septembre 2025
L’automatisation ne fonctionne que si elle repose sur des processus clairs, partagés et normalisés. Sans cartographie, vous risquez surtout d’automatiser… le chaos.
Lire la suite →

18 septembre 2025
Le paradoxe de Moravec à l’ère des IA génératives et ce qu’il révèle sur la vraie valeur du travail humain.
Lire la suite →

7 août 2025
Vous vous sentez dépassé par votre to-do list ? Découvrez comment la transformer en un outil anti-stress grâce à 7 règles basées sur la science du cerveau.
Lire la suite →

4 mai 2025
Je vous propose un petit exercice qui va vous permettre de mieux comprendre votre charge mentale au travail.
Lire la suite →

30 avril 2025
Ce billet répond directement à l'article publié par Clubic le 29 avril 2025 sous le titre « Anthropic a perdu le contrôle de son IA et ne sait pas comment elle fonctionne ». En tant que professionnel du numérique, je souhaite apporter un regard plus nuancé et factuel sur le sujet, en m'appuyant notamment sur le billet très éclairant publié par Dario Amodei, PDG d'Anthropic, le 24 avril dernier.
Lire la suite →
![[Événement] Table ronde à Marseille : déconstruire le mythe de la simplicité en développement web](https://www.lvlup.fr/storage/img/blog/medium/la-plateforme.webp)
24 avril 2025
Le 28 avril prochain, je participerai à une table ronde organisée par La Plateforme_ à Marseille, autour d’un thème que beaucoup d’entre nous rencontrent au quotidien, mais rarement formulé aussi clairement : “Développement Web & Logiciel : déconstruire le mythe de la simplicité.”
Lire la suite →

24 avril 2025
MCP : hype passagère ou véritable nouveau standard ? On a mis les mains dans le cambouis pour se faire une vraie idée.
Lire la suite →
21 avril 2025
OpenAI a publié un guide PDF intitulé "A Practical Guide to Building Agents". Ce document propose un cadre clair et structuré pour débuter avec les agents, notamment dans l’écosystème OpenAI. Il pose de bonnes bases techniques et méthodologiques, même si les exemples restent simples. Une ressource utile pour démarrer ou structurer une première approche des agents LLM.
Lire la suite →

30 mars 2025
Vous pensez qu’un cahier des charges est indispensable avant de lancer votre projet digital ? Découvrez pourquoi cette étape peut freiner votre efficacité et comment une approche opérationnelle, terrain, peut réellement faire avancer votre projet.
Lire la suite →

21 mars 2025
J'ai automatisé la rédaction d'une newsletter pour aider Didier à moins râler le lundi matin...
Lire la suite →

7 mars 2025
Découvrez comment entraîner une IA sur vos propres données pour la rendre plus efficace et pertinente pour votre activité.
Lire la suite →

3 février 2025
De la réflexion au prototype, découvrez comment on monte ce genre de projets.
Lire la suite →

5 décembre 2024
Didier Sampaolo a quitté Bleetic, société qu'il avait cofondé et codirigé avec Rodrigue Fenard.
Lire la suite →

4 décembre 2024
Google utilise désormais les interactions utilisateur comme un puissant indicateur de pertinence et de qualité éditoriale. Les page transitions dans Chrome permettent de comprendre finement le comportement des utilisateurs, au-delà des simples métriques de trafic. En mesurant chaque type de navigation — depuis le clic sur un lien jusqu'à la saisie directe d'une URL — l'algorithme de recherche affine sa compréhension de la valeur réelle d'un contenu.
Lire la suite →
24 octobre 2024
Le torchon brûle dans la communauté WordPress, depuis que Matt Mullenweg a décidé d'attaquer WP Engine.
Lire la suite →

11 octobre 2024
Petite structure, grand groupe : pour implémenter vos projets autour de l'IA, faut-il mieux un bazooka ou un sniper ?
Lire la suite →

9 octobre 2024
Découvrez comment l'automatisation des tâches répétitives peut transformer votre productivité et votre bien-être au travail. LVLUP vous guide vers un environnement professionnel plus efficace et serein.
Lire la suite →
20 juin 2024
Le 9 juin 2024, Kraken, l'une des principales plateformes d'échange de cryptomonnaies, a été alertée par un chercheur en sécurité via leur programme de Bug Bounty. Ce chercheur prétendait avoir découvert une faille critique, qui lui permettait de gonfler artificiellement les soldes des comptes sur la plateforme.
Lire la suite →

3 juin 2024
La documentation de l'API interne de Google a fuité.
Lire la suite →

1 mai 2024
Tour d'horizon des nouveautés de la version 2 de ContentDojo, notre SaaS qui vous aide à trouver des idées pour votre prochain contenu.
Lire la suite →

23 octobre 2023
Découvrez la puissance du 'content repurposing' en SEO. Apprenez à maximiser votre contenu existant, élargir votre audience et renforcer la présence de votre site. Votre jardin digital n'a jamais été aussi florissant !
Lire la suite →

10 octobre 2023
La sécurité, ça doit être un souci permanent, qui demande des efforts constants pour rester au niveau.
Lire la suite →

29 septembre 2023
La version Pro de ChatGPT, qui s'appelle ChatGPT Plus (abonnement à 20€/mois), s'est dotée d'une nouvelle fonctionnalité en beta qui était très attendue (par moi notamment), et qui s'appelle **Advanced Data Analysis**.
Lire la suite →

25 septembre 2023
Après avoir bien galéré, on se permet de vous donner quelques conseils pour communiquer efficacement avec ChatGPT.
Lire la suite →

5 septembre 2023
Plugins et configuration pour développer sereinement des projets Laravel sous VS Code ou Codium.
Lire la suite →

21 août 2023
Nos astuces pour des sessions de brainstorming réussies et productives.
Lire la suite →

4 juillet 2023
Quels réflexes adopter si Google refuse obstinément d'indexer l'une de vos pages ?
Lire la suite →

2 juillet 2023
Améliorez la gestion de vos tâches récurrentes sous WordPress en tirant parti de votre hébergement, qu'il soit dédié ou mutualisé.
Lire la suite →

27 février 2023
Le débat fait rage chez des développeurs depuis que le monde est monde : alors, le vendredi, on met en prod, ou pas ?
Lire la suite →

27 février 2023
Dans le code, le testing, c'est la pierre angulaire du contrôle qualité.
Lire la suite →
27 février 2023
Aimons-nous les uns les autres.
Lire la suite →

27 février 2023
On va parler du rubber duck debugging, méthode beaucoup plus carrée qu'elle n'en a l'air.
Lire la suite →

19 novembre 2019
La question de l'argent semble toujours être taboue, au moins en France. Crevons l'abcès : si on travaille, c'est avant tout pour gagner notre vie. Allez, on parle pognon ?
Lire la suite →