![[Étude] Presse française versus IA : qui bloque quel bot ?](https://www.lvlup.fr/storage/img/blog/big/paperboy-ia-etude.webp)
Clément Pessaux, consultant SEO et éditeur de GNewsalyzer (un dashboard d'analyse de la visibilité sur Google Discover et Google News), nous a contactés pour nous proposer de co-réaliser une étude sur le comportement des grands sites de presse français au regard des robots d'exploration des outils grands public d'intelligence artificielle.
Nous avons examiné les 1328 services de presse reconnus par le Ministère de la Culture en novembre 2025. Parmi eux, 1260 disposent d'une URL valide et 1132 ont un fichier robots.txt accessible.
Notre analyse a consisté à examiner le contenu de ces 1132 fichiers pour y déceler les directives de blocage visant les principaux robots d'IA. Les données datent du 2 novembre 2025.
Méthodologie : distinguer crawlers et bots à la demande
Deux catégories de robots
Nous avons établi une liste de robots en les regroupant selon leur mode de fonctionnement :
- Les crawlers explorent le web de manière autonome à la recherche de contenus. Ils parcourent massivement les sites pour indexer ou collecter des données.
- Les user-triggered accèdent à une page précise à la demande d'un utilisateur. Techniquement, ils ne sont pas tenus de respecter le protocole robots.txt puisqu'ils agissent "on behalf" (au nom) d'un utilisateur.
Les 14 robots analysés
Nous avons retenu 14 robots représentant une large part du marché. Cette liste sera mise à jour avec de nouveaux acteurs : n'hésitez pas à nous signaler ceux qui manqueraient.
Merci à Tyler Einberger, dont la Full List of AI Search Web Crawlers nous a servi de point de départ.
OpenAI (ChatGPT)
- GPTBot (crawler) : collecte massivement le texte public du web pour entraîner les futurs modèles comme ChatGPT et GPT-5
- OAI-SearchBot (crawler) : indexe les pages pour permettre à ChatGPT de faire des recherches et fournir des références web en direct
- ChatGPT-User (user-triggered) : l'ancien robot qui s'activait lorsqu'un utilisateur partageait un lien dans une conversation
- ChatGPT-User 2.0 (user-triggered) : la version actuelle qui remplace la v1.0 pour récupérer le contenu des liens partagés
Anthropic (Claude)
- anthropic-ai (crawler) : collecte des données web à grande échelle pour le développement des modèles Claude
- ClaudeBot (user-triggered) : récupère le contenu des URL citées pendant une session de chat
- claude-web (crawler) : recherche du contenu web récent pour alimenter l'agent de navigation de Claude
Perplexity
- PerplexityBot (crawler) : indexe les sites web pour alimenter le moteur de recherche IA
- Perplexity-User (user-triggered) : s'active lorsqu'une personne clique sur un lien pour le résumer ou l'analyser
Mistral
- MistralAI-User (user-triggered) : récupère le contenu des sources ou citations demandées par Le Chat
Les géants de la Tech
- Google-Extended (crawler) : permet aux sites de bloquer l'utilisation de leur contenu pour l'entraînement des modèles IA (comme Gemini) sans bloquer le SEO (Googlebot)
- AppleBot (crawler) : historiquement utilisé pour Siri, collecte désormais des données pour Apple Intelligence
- Bytespider (crawler) : le robot de ByteDance (TikTok) qui collecte des données pour entraîner ses modèles d'IA
L'archive du Web
- CCBot (crawler) : Le robot de Common Crawl crée des archives publiques massives du web. Ces archives sont ensuite une source de données majeure pour entraîner de nombreux modèles d'IA (OpenAI, Meta, etc.)
La phase d'analyse
Pour chaque fichier robots.txt, nous avons vérifié si chaque crawler était interdit d'accès. Nous n'avons retenu que les blocages s'appliquant à l'intégralité du site.
Résultats : un blocage encore minoritaire, mais concentré
Sur les 1132 sites de presse français disposant d'un fichier robots.txt valide, notre analyse révèle une posture encore minoritaire, mais très concentrée, de blocage.
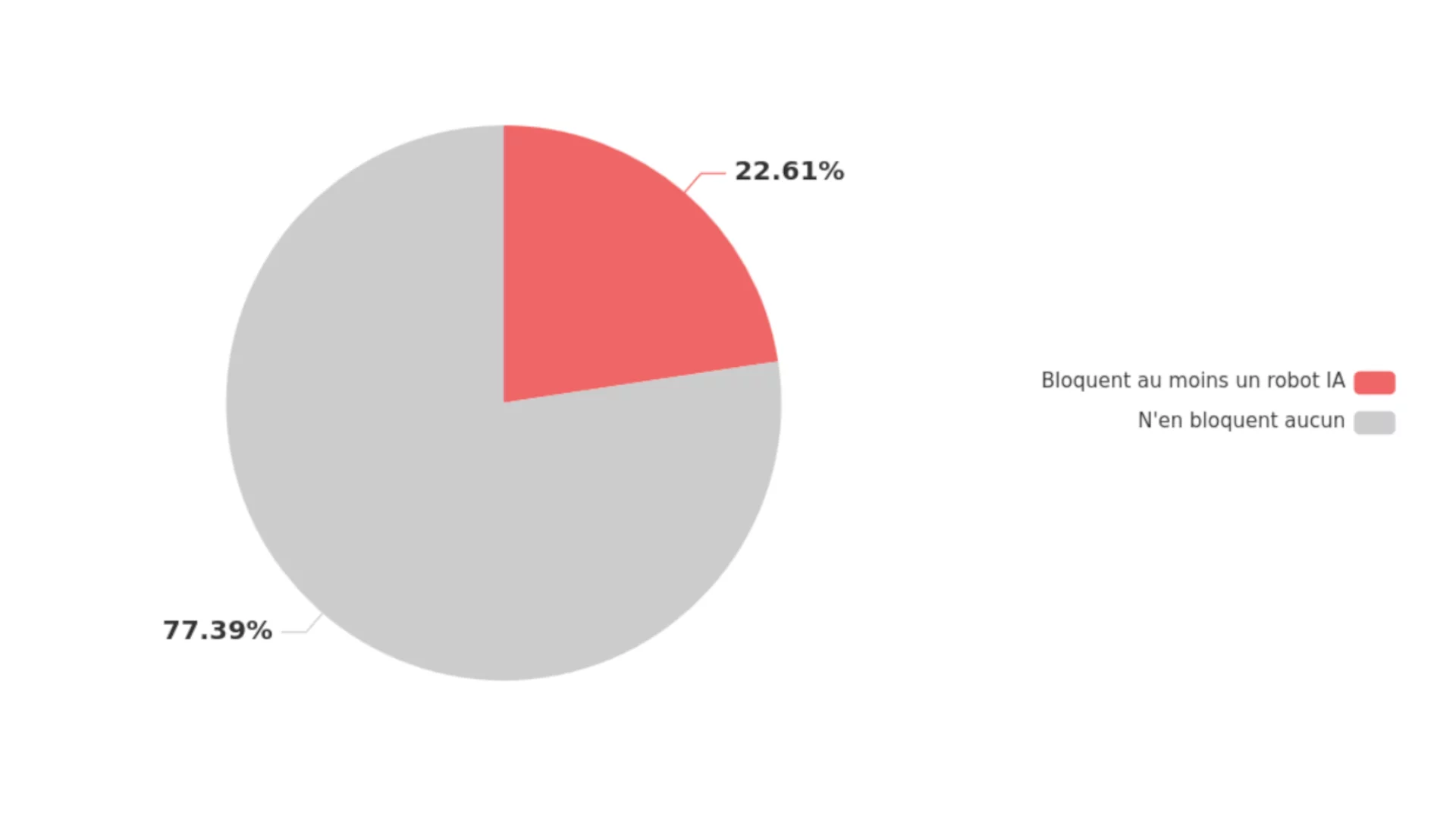
22,6% des sites bloquent au moins un robot IA
Sur les 1132 sites de presse français disposant d'un fichier robots.txt valide, 256 sites (22,6%) bloquent activement au moins un robot d'IA.
À l'inverse, 77,4% des sites n'ont aucune directive de blocage spécifique contre ces robots d'exploration.
Le palmarès des robots les plus bloqués
Les éditeurs de presse ciblent très clairement certains acteurs. Voici le palmarès des robots les plus bloqués :
| Robot | Nombre de sites le bloquant | % de l'échantillon total (1132) |
|---|---|---|
| CCBot | 233 | 20,6 % |
| GPTBot | 220 | 19,4 % |
| ChatGPT-User | 186 | 16,4 % |
| ChatGPT-User 2.0 | 186 | 16,4 % |
| Google-Extended | 174 | 15,4 % |
| Bytespider | 159 | 14,0 % |
| anthropic-ai | 153 | 13,5 % |
| claude-web | 129 | 11,4 % |
| ClaudeBot | 112 | 9,9 % |
| PerplexityBot | 97 | 8,6 % |
| OAI-SearchBot | 54 | 4,8 % |
| MistralAI-User | 34 | 3,0 % |
| AppleBot | 32 | 2,8 % |
| Perplexity-User | 12 | 1,0 % |
Stratégies de blocage : ciblé ou massif ?
Les 256 sites bloqueurs interdisent en moyenne 7,9 robots sur 14. Mais cette moyenne cache des stratégies très différentes :
- Sélectif (1 seul bot) : 31 sites, 12,1 %
- Petit (2 à 4 bots) : 24 sites, 9,4 %
- Moyen (5 à 8 bots) est la norme : 124 sites, 48,4 %
- Large (9 à 12 bots) : 64 sites, 25 %
- Total (tous les bots) : 13 sites, 5,1 %
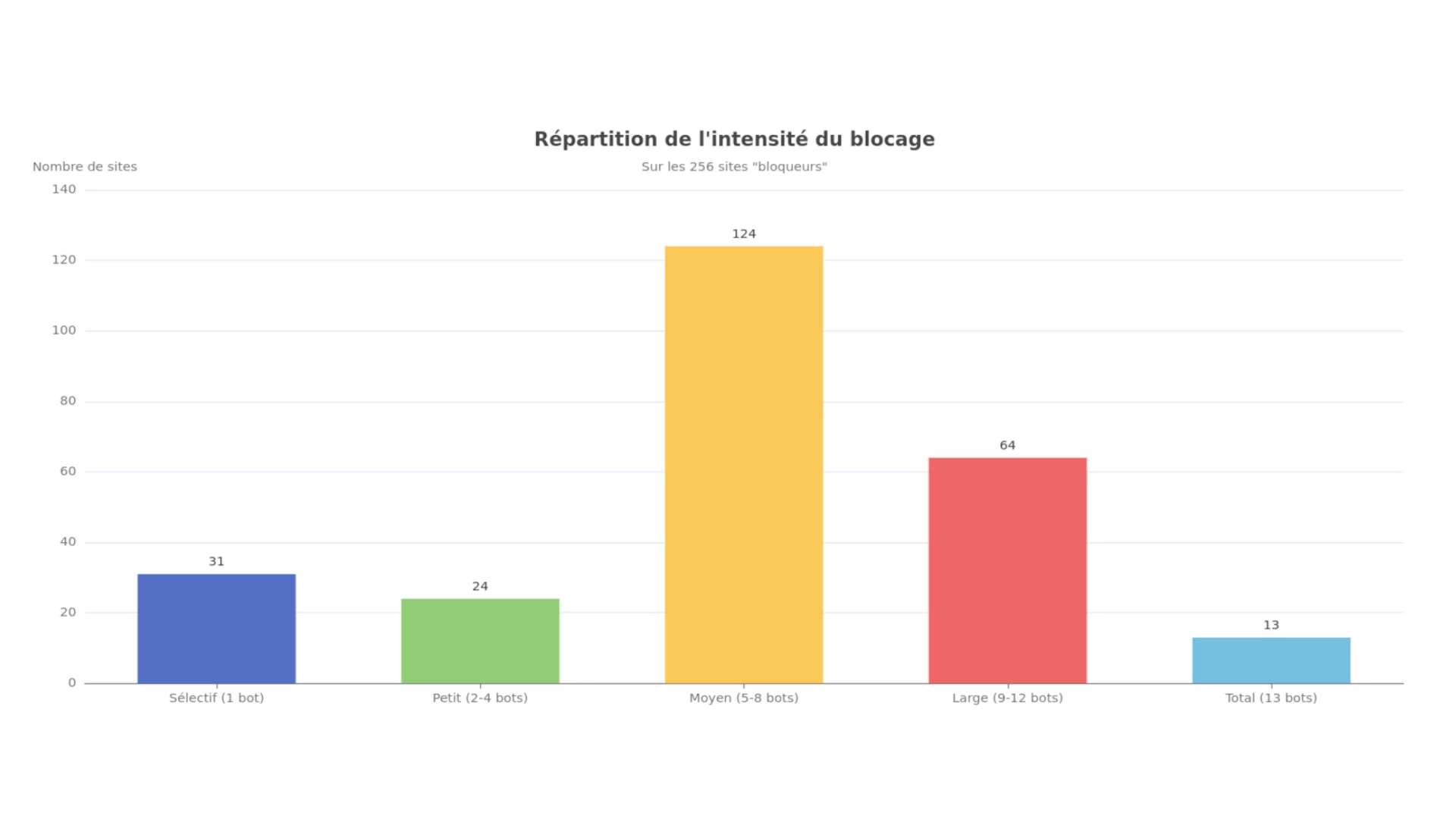
La stratégie "moyenne" domine : les éditeurs ne bloquent ni tout ni rien, mais choisissent les robots qu'ils souhaitent exclure.
CCBot, la cible n°1 : couper l'accès à la source
La plus grande surprise n'est pas le blocage de GPTBot, mais celui de CCBot, le robot le plus bloqué (233 sites, 20,6%).
Contrairement à Google ou OpenAI (même si chez eux, c'est un poil plus compliqué), Common Crawl est une organisation à but non lucratif qui archive massivement le web. Cette archive publique est la source de données n°1 pour l'entraînement d'innombrables modèles d'IA.
Historiquement, OpenAI (pour les premières versions de GPT), Meta et Google ont largement puisé dans ces données. C'est la "base de données par défaut" du web pour quiconque souhaite entraîner un modèle.
La différence stratégique :
- Bloquer GPTBot = refuser l'accès à un acteur spécifique (OpenAI)
- Bloquer CCBot = refuser que son contenu soit versé dans le "pot commun" public, empêchant son utilisation par des milliers de modèles d'IA actuels et futurs
Le fait qu'il soit le plus bloqué révèle une vraie maturité stratégique : les éditeurs ont compris qu'il fallait couper l'accès à la source.
Enseignement surprise : les bots "user-triggered" sont aussi bloqués
Alors que notre méthodologie distingue les crawlers (comme GPTBot) des user-triggered (comme ChatGPT-User), les résultats montrent que les administrateurs bloquent massivement les deux catégories.
Près de 16,4% des sites empêchent ChatGPT-User d'accéder à leurs pages. Or, bloquer ce bot revient à empêcher un utilisateur de ChatGPT d'accéder à un lien de votre site via l'outil.
Deux hypothèses :
- Une incompréhension du fonctionnement de ces robots
- Une volonté de blocage "ceinture et bretelles", visant tout ce qui porte le nom d'une entreprise d'IA
Blocage stratégique ou héritage technique ?
Il est difficile de distinguer la part du blocage "stratégique" (une décision anti-IA récente) de celle du blocage "d'hygiène" (une politique anti-scraping plus ancienne).
Mais le résultat est le même : que ce soit par prévoyance anti-IA ou par héritage technique, CCBot est de facto le robot le plus persona non grata du web de la presse française.
Cette situation coupe l'herbe sous le pied de nombreux modèles d'IA, actuels et futurs, qui dépendent de son archive publique pour leur entraînement.
Le fantôme des droits voisins : la presse ne se fera pas avoir deux fois
Ces blocages massifs, en particulier le tir groupé contre les géants (CCBot, GPTBot, Google-Extended), ne peuvent être compris sans leur contexte : la longue bataille de la presse française pour les droits voisins.
La leçon apprise : l'effet d'aubaine
Pendant près de 20 ans, les éditeurs de presse ont vu les géants de la tech (principalement Google) bâtir des empires en agrégeant leurs contenus, souvent sans juste compensation. Le trafic envoyé en retour a longtemps servi de justification, mais ce "deal" a fini par être perçu comme un marché de dupes.
Le combat pour les droits voisins a été une prise de conscience : le contenu produit par les journalistes a une valeur, et son utilisation par des plateformes tierces doit faire l'objet d'une rémunération.
L'IA : un Google News sous stéroïdes, sans le trafic
Le "deal" (même boiteux) de Google Search ou Google News était : "Je prends ton snippet, je te renvoie du trafic."
Le "deal" de l'IA générative est perçu comme bien plus dangereux : "Je prends l'intégralité de ton contenu, je l'ingère, je le synthétise, et je réponds à l'utilisateur à ta place. Je ne te renvoie aucun trafic."
Pour un éditeur dont le modèle économique repose sur l'audience (publicité, abonnements), c'est une menace existentielle.
Le blocage comme levier de négociation
Échaudés par l'âpreté des négociations sur les droits voisins, les éditeurs français ont compris la leçon : bloquer d'abord, négocier ensuite.
Ils ne répéteront pas l'erreur de laisser un écosystème se bâtir gratuitement sur leur dos. En bloquant GPTBot, CCBot ou Google-Extended maintenant, ils créent un vide. Ils empêchent les modèles de se nourrir de leurs contenus — souvent les plus qualitatifs et les plus frais du web francophone.
Cette stratégie vise à forcer OpenAI, Google et les autres à venir à la table des négociations pour établir des licences d'exploitation. Le blocage n'est pas une fin en soi, c'est un levier commercial.
Google-Extended : la preuve vivante de cette tension
Le fait même que Google ait créé le user-agent Google-Extended prouve que ce sujet est brûlant.
Google, également échaudé par les amendes et les procès sur les droits voisins, a compris qu'il ne pouvait pas mélanger le crawl pour le SEO (couvert par les accords de droits voisins) et le crawl pour l'entraînement de l'IA (un nouveau terrain de jeu juridique).
En créant Google-Extended, Google donne aux éditeurs un interrupteur ciblé. Le fait que 174 sites de presse l'utilisent déjà montre qu'ils ont sauté sur l'occasion.