Vous connaissez cette situation. Un nouveau modèle de LLM sort, les benchmarks sont excellents. Vous l'intégrez dans vos outils, copiez-collez vos prompts habituels et... déception. Les résultats sont moins bons qu'avant, parfois même ratés.
Votre premier réflexe ? Blâmer le modèle. Mais Max Leiter, qui travaille sur v0 chez Vercel, pose une question intéressante dans son article "You should be rewriting your prompts" : et si c'était nous le problème ?
Son constat est simple : on parle beaucoup du surajustement des modèles aux données, jamais du surajustement de nos prompts aux modèles.
Chaque IA a son dialecte
Prenez les modèles OpenAI. Ils adorent le Markdown. Normal, ils ont été nourris avec tout Internet, où ce format est omniprésent. Vos prompts structurés avec des # et des ** marchent parfaitement.
Puis Claude d'Anthropic arrive. Mêmes prompts, résultats moyens. Pourquoi ? Claude préfère le XML. Anthropic le dit clairement dans sa documentation :
Les balises XML peuvent changer la donne. Elles aident Claude à analyser vos prompts plus précisément.
Utilisez <instructions>, <contexte>, <exemple> pour délimiter vos sections. Pour Claude, c'est la différence entre parler sa langue maternelle ou baragouiner dans un dialecte étranger.
L'angle mort du milieu de contexte
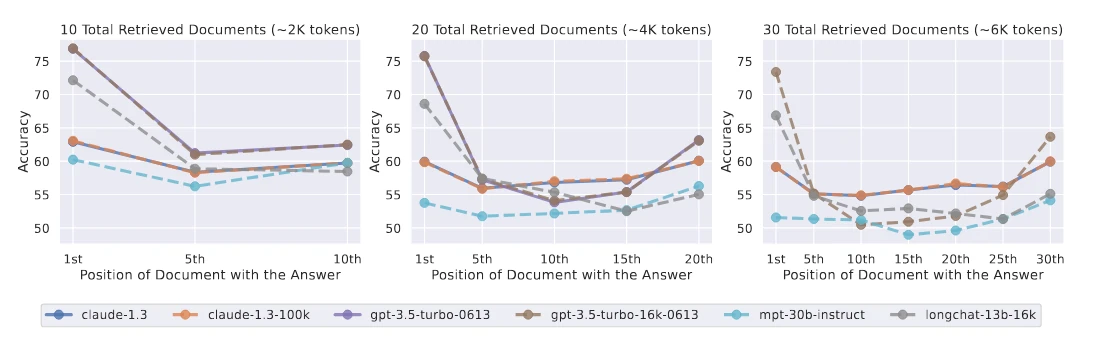
Leiter soulève un point encore plus subtil : l'ordre des mots compte énormément. Une étude de Stanford, "Lost in the Middle", montre que les modèles ont une mémoire en forme de U.
Ils excellent à retenir ce qui est au début ou à la fin d'un long texte, mais oublient ce qui traîne au milieu. Si vous donnez 30 pages à analyser, mettez votre question principale en première ou dernière page, pas à la page 15.
C'est lié à l'architecture des Transformers : leurs mécanismes d'attention ont naturellement du mal avec le centre des longs contextes.
Arrêtez de vous battre contre la personnalité de l'IA
Chaque modèle a sa personnalité, ses biais hérités de l'entraînement. On passe notre temps à les contrer avec des rustines : "Sois concis", "Ne te répète pas", "Évite de dire 'En tant que modèle de langage...'".
Ces corrections étaient utiles sur les anciens modèles, souvent bavards. Pendant l'entraînement RLHF, les évaluateurs humains préféraient inconsciemment les réponses longues, les associant à plus de qualité. Résultat : les IA ont appris que "plus long = mieux".
Aujourd'hui, les créateurs corrigent ces défauts à la source. Claude utilise l'IA Constitutionnelle : au lieu de dépendre seulement des retours humains, il suit une "constitution" inspirée de textes comme la Déclaration des Droits de l'Homme. Ça le rend naturellement prudent et sécuritaire.
Essayer de forcer Claude à prendre des risques, c'est lutter contre sa programmation de base. Autant pousser une voiture en panne au lieu de regarder sous le capot.
L'approche intelligente ? Apprendre la personnalité du modèle pour l'utiliser à votre avantage. Si un modèle aime la structure, demandez-lui des tableaux. S'il est créatif, donnez-lui de la liberté.
Un enjeu de performance, pas juste de confort
S'adapter aux modèles, ce n'est pas du perfectionnisme de développeur. C'est de la performance pure.
- Coût : Des prompts mal adaptés nécessitent plusieurs tentatives, consomment plus de tokens, coûtent plus cher.
- Temps : Lutter contre les biais d'un modèle augmente la charge mentale et la friction. Mauvaise ergonomie numérique.
- Conformité : Un modèle qui interprète mal vos instructions peut produire des résultats non conformes (RGPD, IA Act) ou nécessiter une validation humaine systématique. Votre gain d'automatisation disparaît.
L'artisanat du dialogue machine
Travailler avec l'IA n'est pas une science exacte où une formule marche à tous les coups. C'est un artisanat, un dialogue constant où il faut réapprendre à connaître son interlocuteur à chaque nouveau modèle.
La question reste ouverte : cette fragmentation est-elle temporaire ? Verra-t-on un jour des IA "polyglottes", capables de s'adapter à n'importe quel style d'instruction ? Ou le rôle de "traducteur" entre l'humain et la machine deviendra-t-il une compétence centrale pour tous ?
En attendant, la règle d'or reste simple : adaptez vos prompts aux modèles, pas l'inverse.