L'arrivée quasi simultanée des trois nouveaux "frontier models" (GPT-5.1, Gemini 3 et Claude Opus 4.5) confirme une tendance de fond : le marché bascule des chatbots conversationnels vers les agents autonomes. Pour les équipes techniques, la priorité n'est plus le savoir encyclopédique, mais la fiabilité d'exécution sur des tâches complexes, notamment axées autour de la génération de code (refactoring, orchestration de données) sans supervision humaine constante.
SWE-bench : La prime à la fiabilité
Avec 80,9 % de réussite sur SWE-bench Verified, Opus 4.5 reprend la tête du classement.
Pourquoi ce benchmark compte
Ce benchmark est devenu le standard industriel car il évalue la capacité à résoudre des bugs réels sur des dépôts GitHub, contrairement aux tests de fonctions isolées. Le modèle doit naviguer dans l'architecture, respecter les conventions existantes et passer les tests d'intégration.
Classement actuel
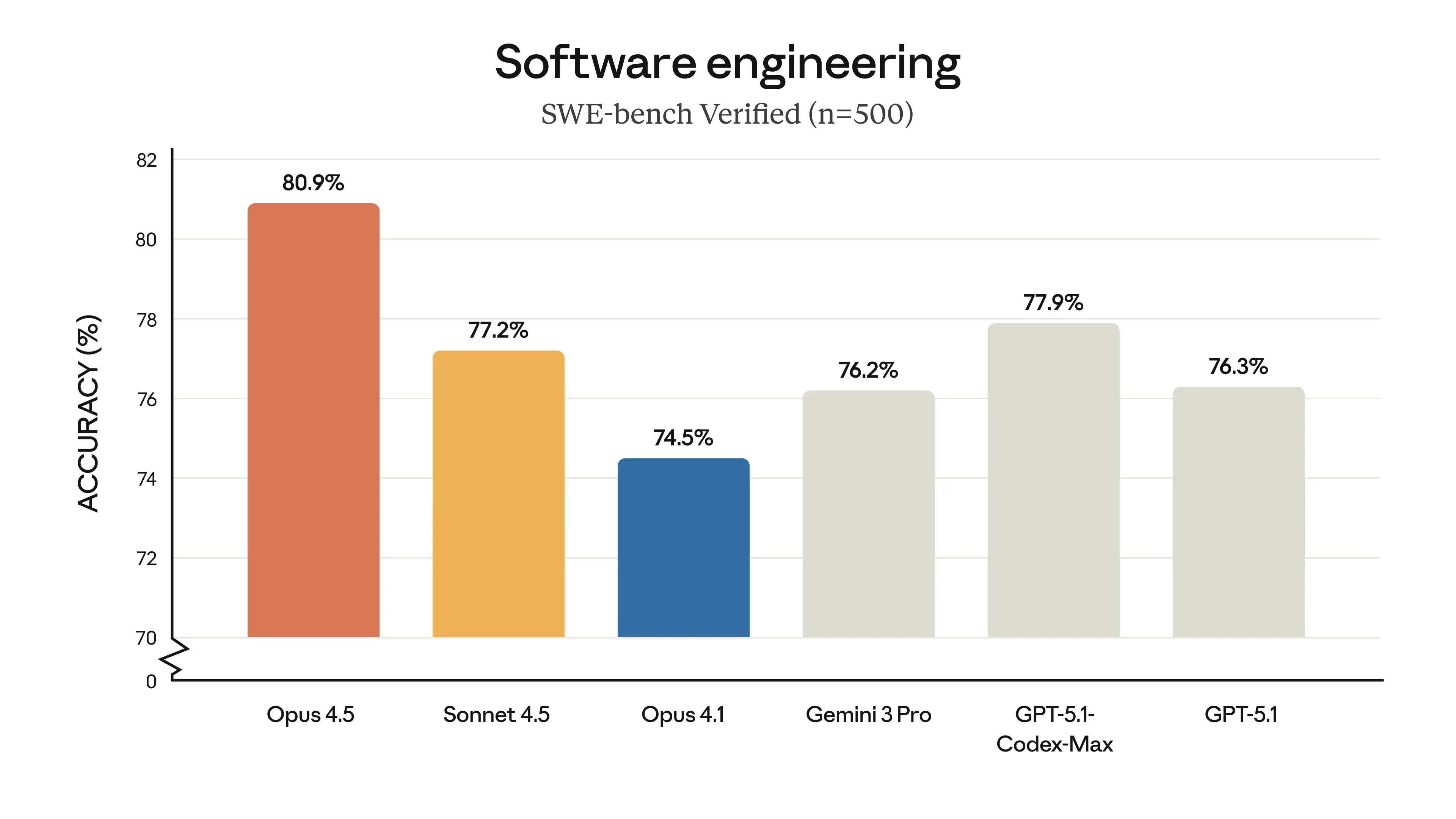
- Opus 4.5 : 80,9 %
- GPT-5.1 Codex Max : 77,9 %
- Sonnet 4.5 : 77,2 %
- Gemini 3 : 76,2 %
Si les écarts semblent minces, ils sont critiques en production. Un taux de réussite "one-shot" plus élevé réduit drastiquement les boucles d'erreurs, économisant à la fois des tokens et du temps de validation humaine.
Le coût du raisonnement : paramètre "Effort" et Pricing
Opus 4.5 introduit une granularité nouvelle dans la gestion des coûts via le paramètre "effort".
Une consommation à la carte
Le modèle permet d'alterner entre deux modes selon la tâche :
- Mode Routine (Faible/Moyen) : idéal pour les hauts volumes. Il offre une performance équivalente à Sonnet 4.5 tout en consommant 76 % de tokens en moins.
- Mode Complexe (Élevé) : il active les "thinking blocks" (raisonnement profond). Le modèle planifie et s'autocorrige avant de répondre, offrant un gain de 4,3 points sur SWE-bench. On ne paie ce surcoût de calcul que lorsque la difficulté l'exige.
Nouvelle grille tarifaire et impact du Caching
Face à l'agressivité tarifaire de GPT-5.1 (1,25 $/10 $ - par million de tokens) et Gemini 3 (2 $/12 $), Anthropic réajuste son offre.
- Tarifs : 5 $(entrée) / 25$ (sortie). C'est trois fois moins cher que la génération précédente, mais cela reste significativement plus cher que chez OpenAI notamment.
- Rentabilité réelle : Le pari d'Anthropic est que la fiabilité compense le coût unitaire. Si Opus 4.5 résout un problème complexe du premier coup pour 0,50 $, il reste plus rentable qu'un modèle moins cher nécessitant trois tentatives.
- L'atout Prompt Caching : Pour les agents travaillant sur des contextes statiques (documentation, base de code), le cache réduit le coût de lecture de 90 % (0,50 $ le million). C'est ce mécanisme qui permet à Opus 4.5 de s'aligner économiquement sur la concurrence pour les tâches répétitives.
Gestion du contexte : Context Editing et Compaction
C'est sur la gestion de la mémoire que les évolutions sont les plus techniques. Contrairement à une simple augmentation de la fenêtre contextuelle, Opus 4.5 propose des outils pour gérer activement ce qui est retenu.
Context editing (Côté Serveur)
Cette fonctionnalité permet de nettoyer l'historique de conversation (API) pour rester dans les limites sans perdre l'essentiel :
- Tool result clearing : Supprime les résultats d'outils anciens (souvent verbeux) tout en gardant la trace de leur exécution.
- Thinking block clearing : Permet de supprimer les blocs de pensée des tours précédents pour économiser du contexte, ou de les conserver ("Preservation") pour maximiser le "Prompt Caching".
Compaction (Côté Client/SDK)
Disponible dans le SDK Python/TypeScript, la compaction résout le problème des tâches longues (agents "always-on"). Lorsque la conversation atteint un seuil défini (ex: 100k tokens), le SDK déclenche automatiquement un résumé structuré de l'historique, remplace la conversation passée par ce résumé, et permet à l'agent de continuer sans saturer sa fenêtre contextuelle.
Comparatif technique : 3 architectures, 3 usages
Le marché n'est plus monolithique, il se segmente par cas d'usage.
Gemini 3 : L'échelle et la multimodalité
Google mise tout sur la capacité d'absorption avec une fenêtre contextuelle massive de 1 à 2 millions de tokens et une multimodalité native. Cette architecture en fait l'outil de référence pour l'analyse de données non structurées, capable d'ingérer des vidéos entières ou des bases documentaires lourdes en un seul prompt. Sa limite principale reste une précision moindre sur la génération de code pur par rapport aux standards imposés par Claude.
GPT-5.1 : Le volume et l'efficience
OpenAI joue la carte du prix plancher pour dominer les usages à fort volume. Ce modèle s'impose naturellement pour les flux "always-on" et les processus répétitifs à grande échelle où la maîtrise du coût opérationnel prime sur la profondeur d'analyse. En contrepartie, son taux de succès "one-shot" est inférieur, ce qui le disqualifie souvent pour les tâches critiques nécessitant une fiabilité absolue sans itérations.
Opus 4.5 : La précision et la mémoire gérée
Anthropic assume un positionnement premium focalisé sur la densité de raisonnement et la gestion de l'ambiguïté. Il constitue le choix par défaut pour les tâches à haute valeur ajoutée, comme la sécurité ou le refactoring métier complexe. Pour compenser sa fenêtre de 200 000 tokens, le modèle introduit désormais des fonctionnalités de "Context Editing" et de "Compaction" (via le SDK), permettant de nettoyer ou résumer dynamiquement l'historique pour traiter des tâches longues sans recourir systématiquement au RAG.
Advanced Tool Use et intégration MCP
Opus 4.5 introduit trois fonctionnalités en beta pour résoudre les problèmes d'échelle des agents, en complément du Model Context Protocol (MCP) qui standardise l'accès aux données.
Le raisonnement imbriqué (Interleaved Thinking)
Jusqu'ici, les modèles traitaient les appels d'outils de manière séquentielle. Avec l'option interleaved thinking, Opus 4.5 peut générer des blocs de pensée entre les exécutions d'outils. Techniquement, cela permet au modèle d'analyser le tool_result (le retour d'une commande ou d'une API) avant de décider de l'action suivante. Si une commande échoue ou renvoie une donnée inattendue, le modèle utilise ce bloc de réflexion intermédiaire pour ajuster ses paramètres au lieu de boucler sur une erreur ou d'arrêter l'exécution.
Gestion dynamique des outils : Tool Search
L'injection de toutes les définitions d'outils dans le prompt système (System Prompt) sature rapidement la fenêtre contextuelle et augmente les coûts/latence. La fonctionnalité Tool Search contourne cette limite technique. Le modèle ne charge pas tous les outils en mémoire ; il a accès à un outil de recherche qui lui permet de requêter un index pour trouver la fonction pertinente au moment T. Cela permet théoriquement de connecter un agent à des milliers d'outils sans impacter la taille du prompt initial : c'est la même technologie que derrière le "progressive disclosure" embarqué avec les Claude Skills.
L'apport du standard MCP
Ces capacités s'appuient sur le Model Context Protocol (MCP). Ce protocole fournit une interface standardisée pour connecter le modèle à des ressources externes (bases de données, systèmes de fichiers, dépôts Git). Au lieu de développer des intégrations spécifiques pour chaque source de données, les développeurs exposent leurs ressources via des serveurs MCP. Pour Opus 4.5, ces ressources sont traitées comme des outils natifs, simplifiant l'architecture des agents qui doivent interagir avec des environnements techniques hétérogènes.