
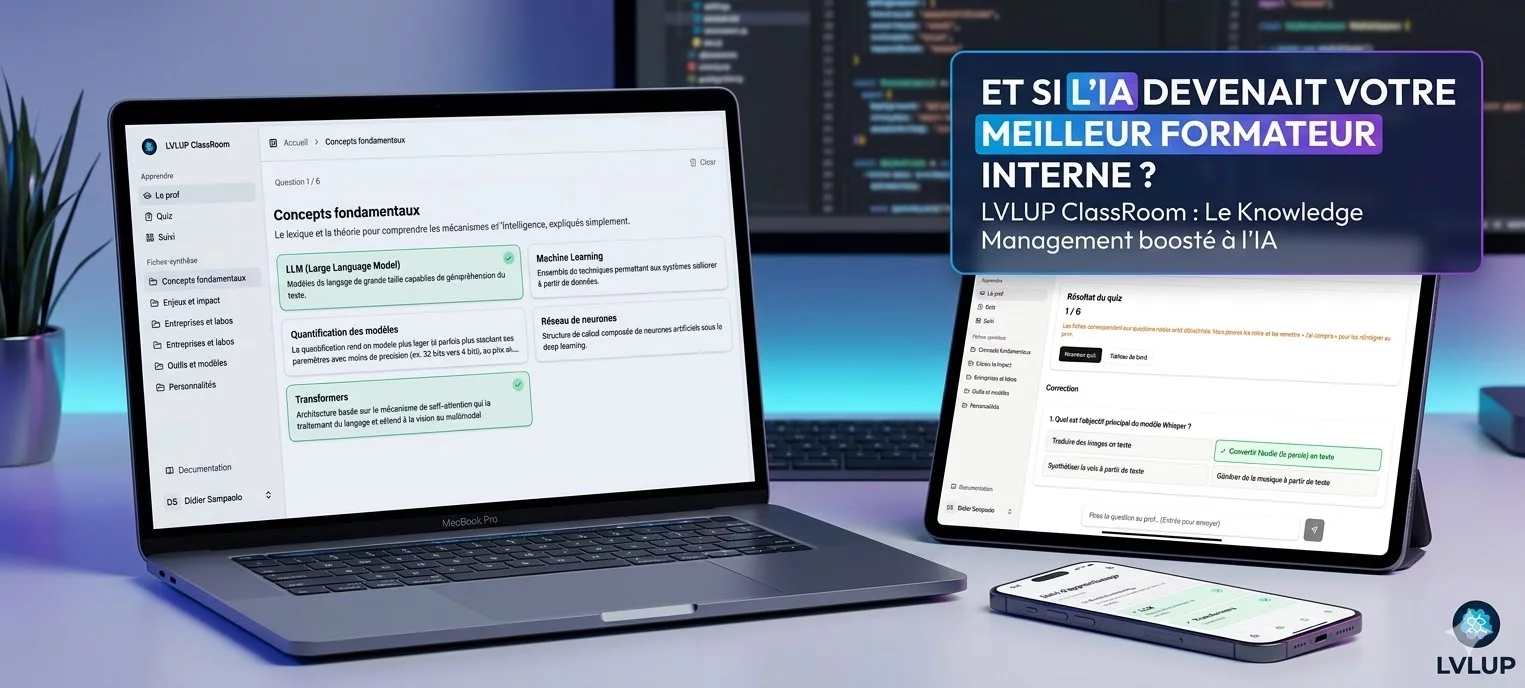
Et pour l'occasion, on va ouvrir les portes du lab' pour vous montrer un prototype qu'on utilise beaucoup en interne : LVLUP ClassRoom.
Pour cette démonstration, nous avons configuré notre agent "Professeur" pour enseigner les concepts liés à l'IA. Mais comme vous allez le voir, la mécanique sous-jacente ouvre des perspectives bien plus vastes pour vos propres données.
Petite visite guidée.
Un assistant pédagogique sur-mesure et multi-modes
Contrairement à un ChatGPT classique où l'utilisateur se retrouve face à une page blanche, notre interface guide l'apprentissage.
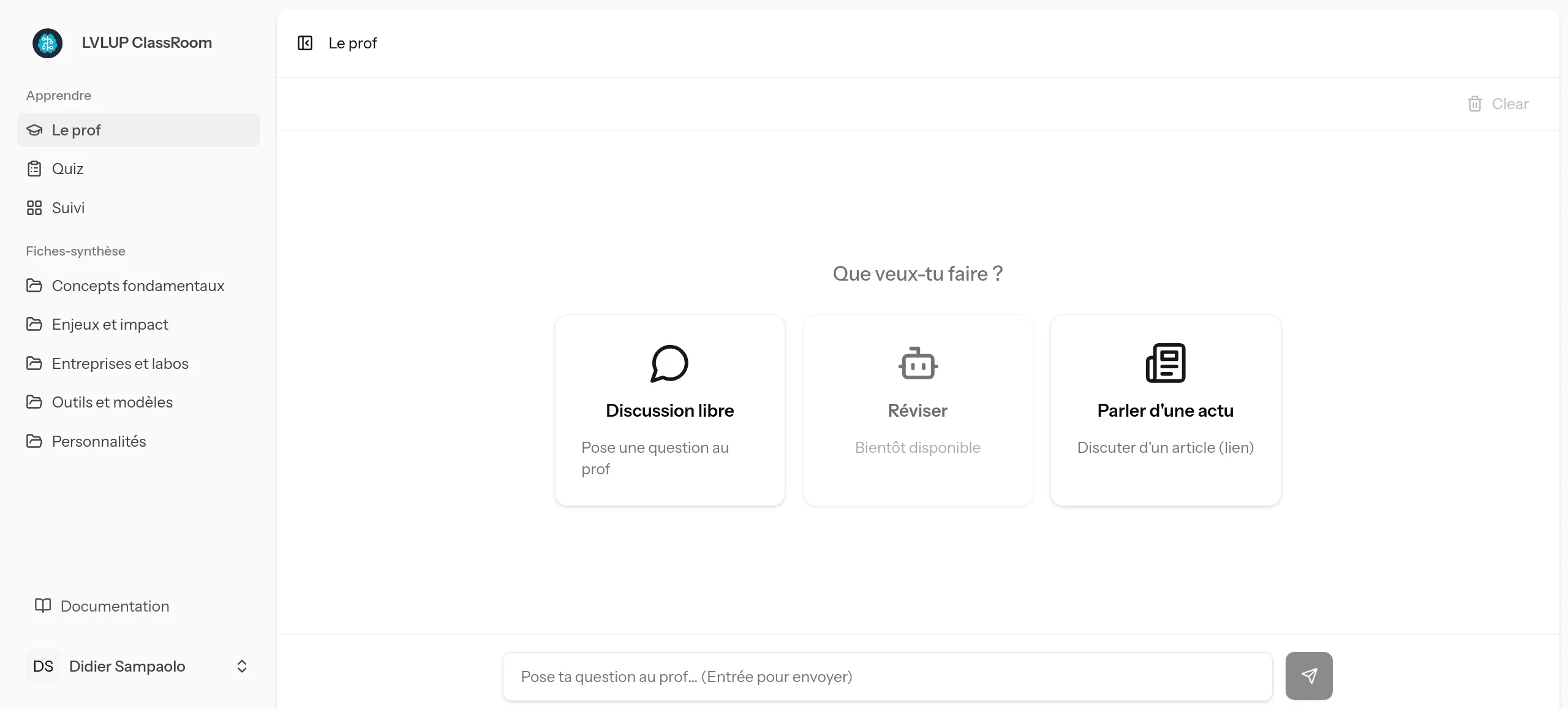
L'utilisateur a le choix entre plusieurs modes d'interaction. Il peut poser une question libre ("qui est le patron d'Anthropic ?") et obtenir une réponse claire, formatée et contextualisée par notre agent.
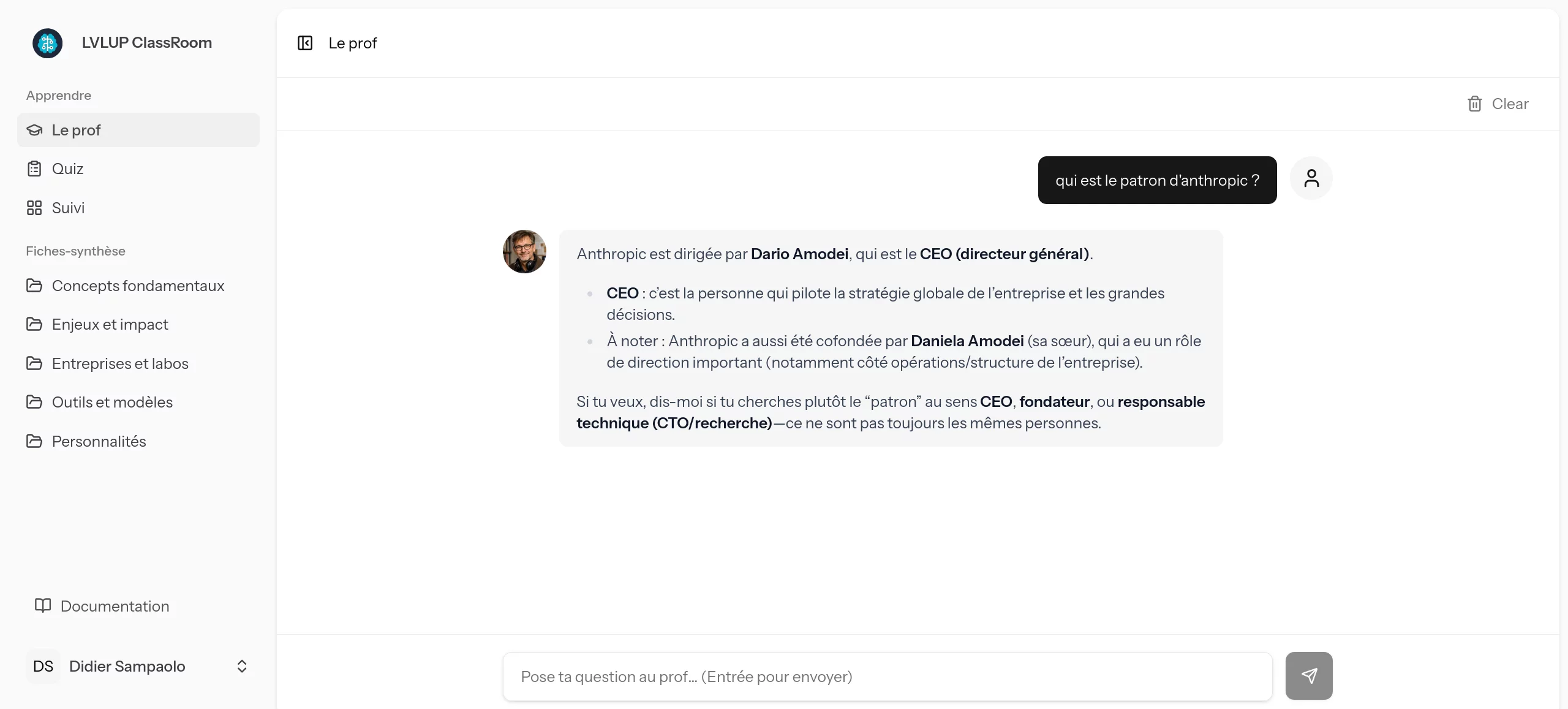
Mieux encore : l'IA est capable d'interagir avec le monde réel. En lui fournissant l'URL d'un article d'actualité, l'agent peut le lire, le synthétiser et en débattre avec l'apprenant pour vérifier sa compréhension.
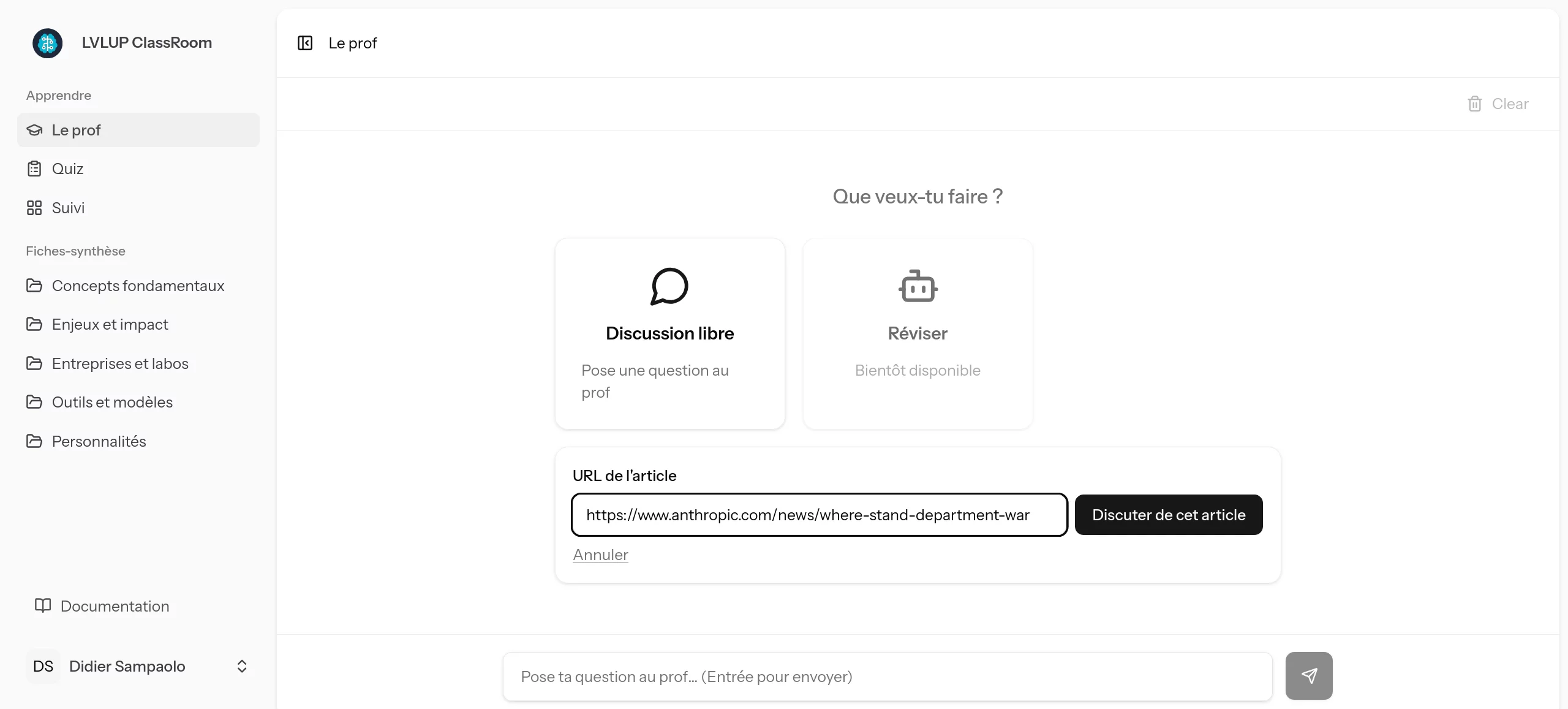
Mais ça va plus loin : ce mode "Actu" confronte directement la nouveauté à votre base de connaissances existante. Si l'article apporte de nouvelles informations (une nouvelle version d'un modèle, un changement de paradigme), l'agent met à jour automatiquement les fiches d'apprentissage correspondantes. Fini la documentation obsolète.
Pousser la réflexion plus loin
Un bon professeur ne se contente pas de donner la réponse, il invite à creuser. Lorsque l'agent explique un concept complexe (comme la quantification des modèles), il définit les termes de jargon, utilise des analogies simples, puis propose des boutons d'approfondissement ("Approfondir : PTQ vs QAT", "INT8 vs 4-bit").
L'apprentissage se fait à la carte et s'adapte à l'utilisateur : le système permet de définir des niveaux de complexité (débutant, intermédiaire, expert) pour que le vocabulaire et la profondeur technique soient toujours ajustés à la cible.
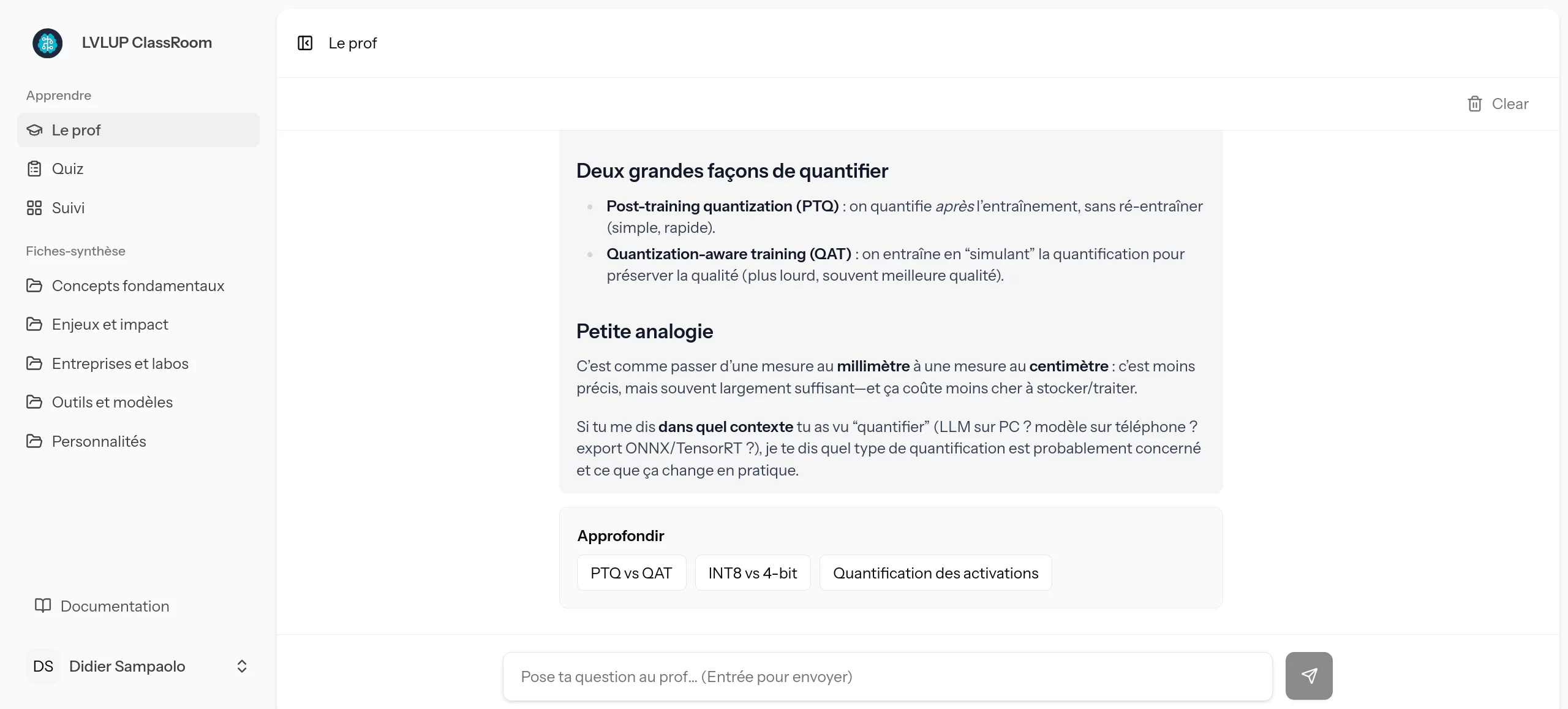
Structurer le savoir : de la conversation à la base de connaissances
C'est ici que la magie du Knowledge Management opère. Une simple conversation avec une IA est volatile. Pour un apprentissage réel, il faut de la structure.
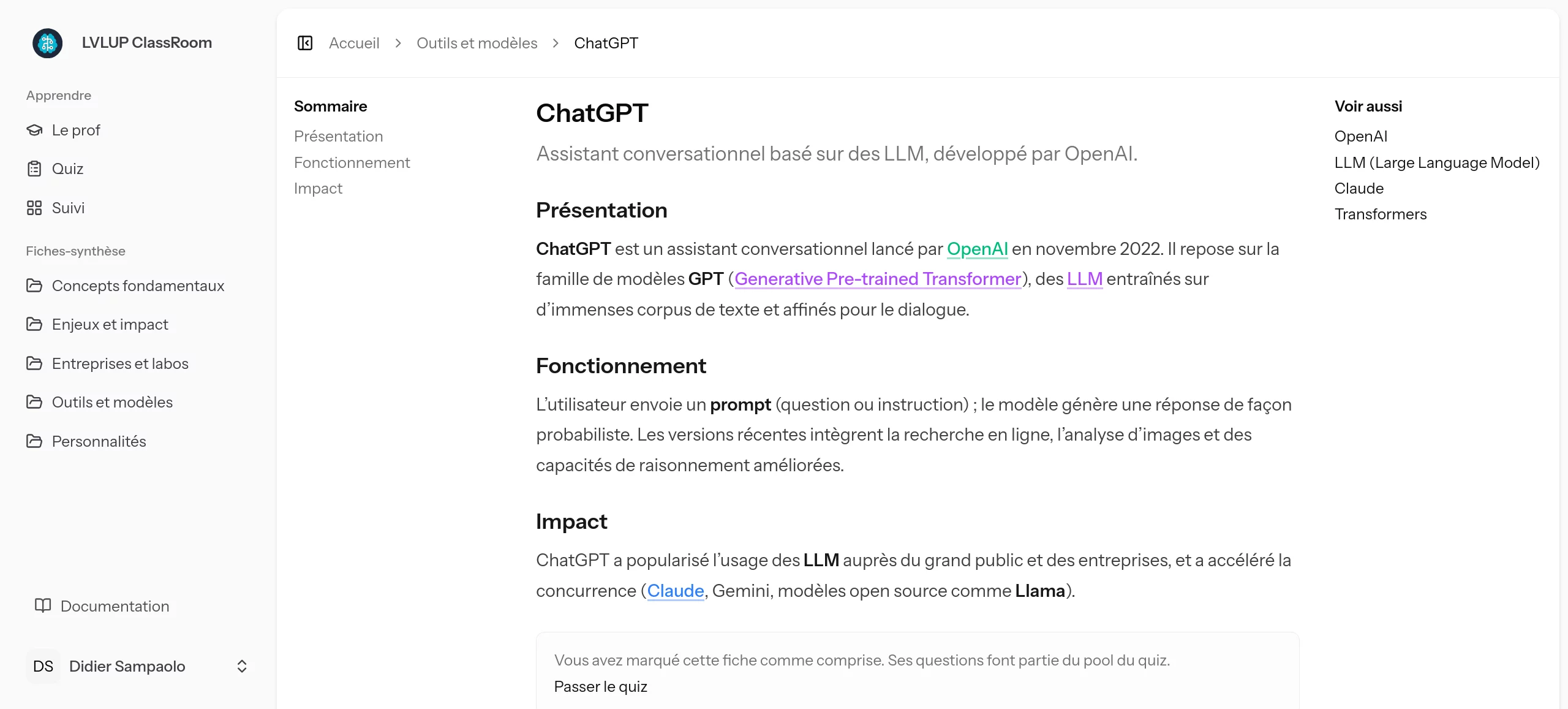
C'est pourquoi l'application génère et met à disposition des Fiches-synthèse. Chaque concept (LLM, Transformers, ChatGPT...) possède sa propre fiche, claire et concise.
Surtout, ces fiches sont inter-linkées automatiquement (avec un code-couleur par catégorie) pour permettre à l'utilisateur de sauter d'un concept à l'autre de manière fluide. Pas de liens créés à la main ici : notre moteur utilise des embeddings (la transformation du texte en vecteurs mathématiques) pour calculer la proximité sémantique entre les concepts et créer des ponts intelligents.
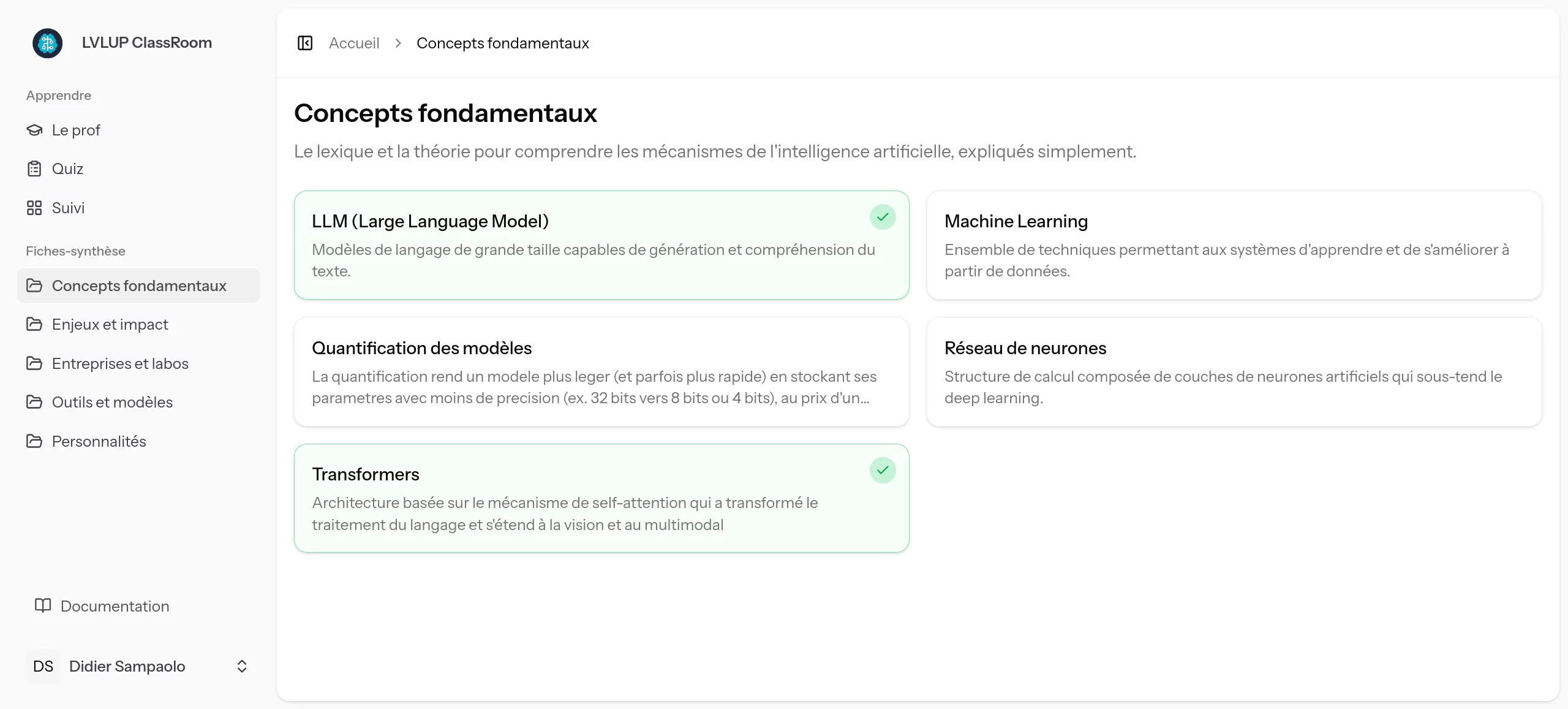
Une fois la fiche lue, l'utilisateur indique qu'il l'a comprise. Cela alimente directement son Suivi d'apprentissage, un tableau de bord visuel (avec un système de checkmarks verts) qui permet de voir en un clin d'œil ce qui est acquis et ce qui reste à explorer.
Valider les acquis
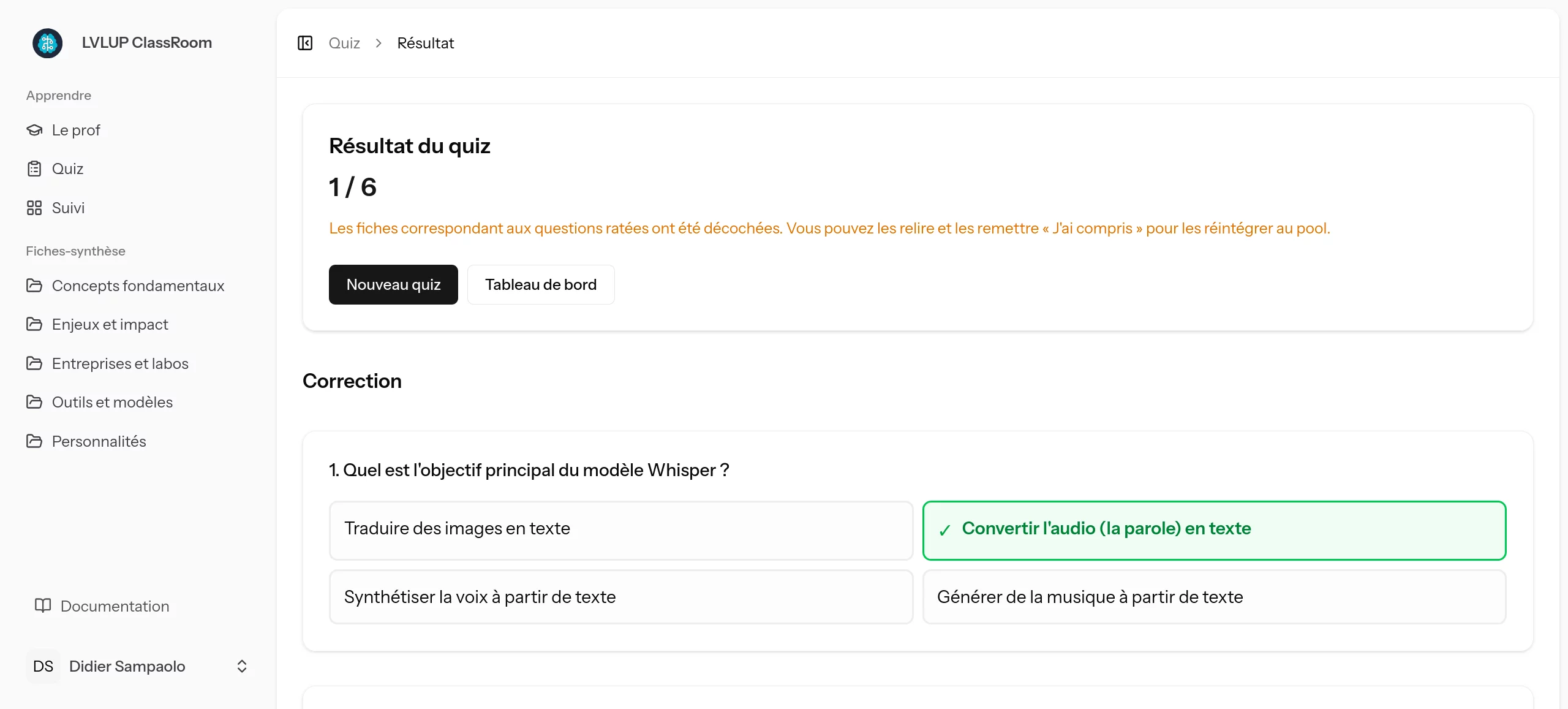
Pour s'assurer que les concepts sont réellement maîtrisés, l'application génère dynamiquement des quiz. Les questions ne sont pas piochées dans une banque de données statique : elles sont générées en temps réel par l'IA à partir du contenu exact des fiches validées.
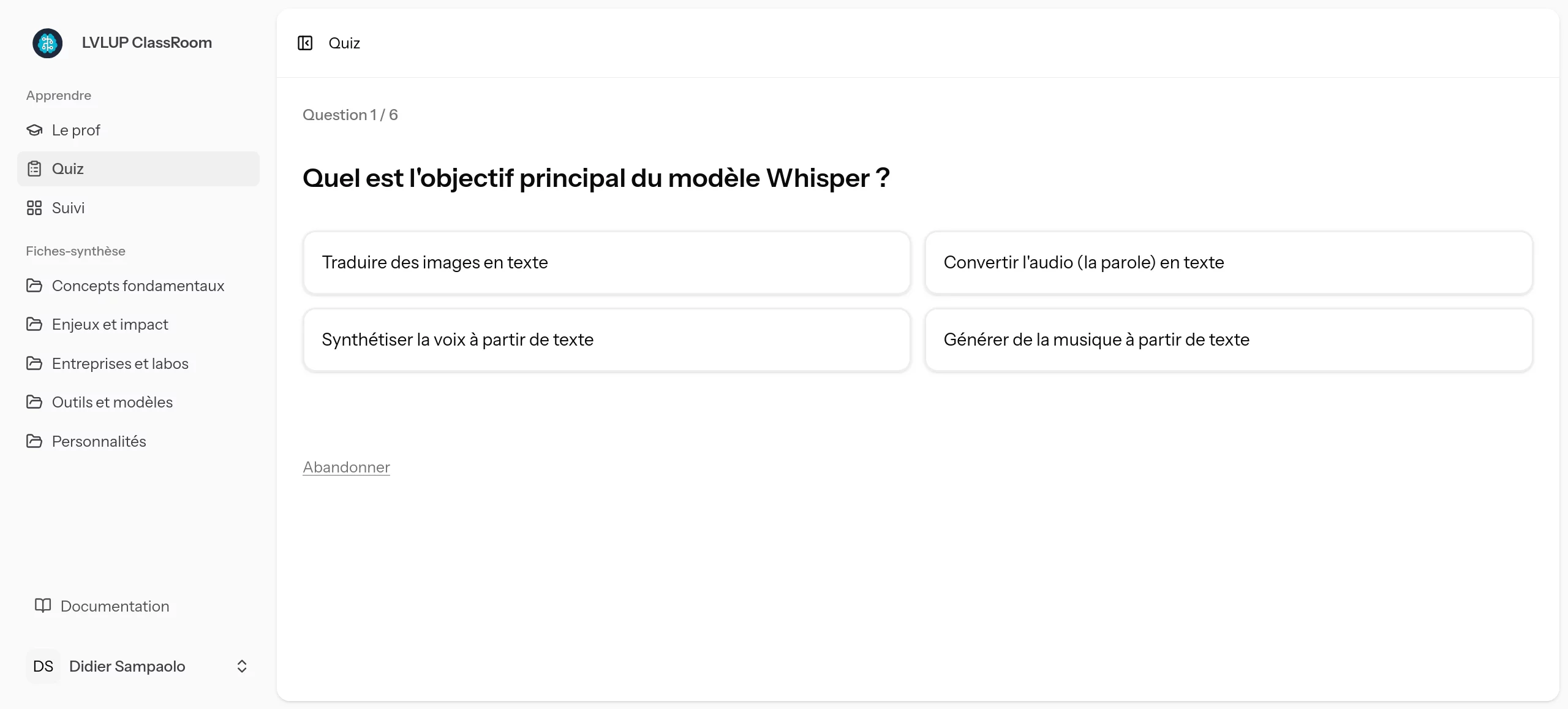
L'agent agit d'ailleurs en véritable relecteur : en analysant les fiches, il est capable d'identifier les "gaps" (informations manquantes ou imprécises) et de les corriger de lui-même pour garantir la pertinence des tests.
Et parce que l'erreur fait partie de l'apprentissage, le système est intelligent : si une question est ratée, la fiche de synthèse correspondante est automatiquement "décochée" dans le suivi de l'utilisateur. Il sait ainsi exactement ce qu'il doit réviser.
Sous le capot : Flexibilité technique et Souveraineté
Faire une belle interface, c'est bien. Avoir une architecture robuste et sécurisée derrière, c'est mieux.
Le moteur LLM qui propulse ClassRoom, qui génère les réponses et calcule les vecteurs, est 100% configurable selon vos contraintes :
- Performance brute : Nous pouvons plugger l'outil via API aux modèles commerciaux les plus performants du marché (GPT-5 chez OpenAI, Claude chez Anthropic, ou Gemini chez Google).
- Souveraineté et sécurité absolue : Vos données sont critiques (Défense, Santé, R&D, secrets industriels) ? Nous pouvons déployer le système en local, en faisant tourner l'inférence de modèles Open Source directement sur un serveur dédié privé. Aucune donnée ne sort de votre infrastructure.
Au-delà de la démo : Imaginez cela avec vos données
Dans cet exemple, notre agent enseigne l'Intelligence Artificielle. Mais notre moteur est agnostique. Imaginez le même dispositif, mais connecté de manière sécurisée (via ce qu'on appelle le RAG - Retrieval-Augmented Generation) à votre base documentaire, vos manuels internes ou vos programmes de formation :
- Ressources Humaines : Un outil d'onboarding ultime. Le nouvel employé interagit avec les procédures de l'entreprise, le règlement intérieur et les fiches métiers, avec des quiz pour valider son intégration.
- Support et documentation technique : Vos techniciens se forment sur des manuels machines complexes de plusieurs centaines de pages, l'IA leur vulgarisant les passages ardus et testant leurs connaissances avant une intervention.
- Éducation : Un accompagnement sur-mesure basé sur le programme scolaire officiel, capable de ré-expliquer un théorème de maths de cinq façons différentes jusqu'à ce que l'élève comprenne.
Concevoir ce type d'outil demande bien plus que d'appeler une API. Il faut structurer la donnée, maîtriser le prompt engineering pour garantir le ton et la justesse pédagogique, et concevoir une interface (UI/UX) qui rend l'expérience fluide et engageante. C'est exactement ce que nous aimons construire.